
Click Forensics is calling this the Internet marketing potential fraud behavior - "Bahama botnet" because initially it was redirecting traffic through 200,000 parked domains in the Bahamas, although it now is using sites in Amsterdam, the U.K. and Silicon Valley.
HTML tag Iframes can be very flexible too and is said to be potential source for the fraud - "Bahama botnet"; much less constrained than a "framed" page. They can be a great way to add an "update" section to a page without having to worry about the size of the new content.
Iframes place a smaller "box" containing another HTML document inside the larger main display. It's like having a smaller window inside the main window to display a separate source of information. Frames split an entire window into two or more sections. Frames run edge to edge rather than being a box placed somewhere inside.
Click fraud affects marketers who spend money on pay-per-click (PPC).
Sophisticated Botnet Causing a Surge in Click Fraud
Study: Half Of Ad Impressions, 95 Percent Of Clicks Fraudulent
NYtimes.com Ad Scam Linked to 'Bahama' Botnet
Click Fraud's New Asian Connection
Yahoo! Cozies Up To Its Click-Fraud Critics
Click Fraud Goes Viral
Google Defends Its Clicks
Note: First introduced by Microsoft Internet Explorer in 1997 and long only available in that browser, the iframe tag is now widely supported by visual browsers. Unlike an object element, an inline frame may be the "target" frame for links defined in other elements and it may be "selected" by a browser as the focus for printing, viewing HTML source etc.
Showing posts with label Business Intelligence. Show all posts
Showing posts with label Business Intelligence. Show all posts
Wednesday, September 23, 2009
Saturday, August 15, 2009
BI can lay stepping stone for Fraud Analytics!
Fraud losses can impact every business. Fraud Analytic differs from Business Intelligence(BI) type Analytic with relatively higher human interaction and deep dive, but it's all about data. Understanding of data and visual representation can provide early alert, enabling users to take timely action to stop fraud and halt losses. A proactive approach will combat fraudulent behavior and increase the perceived value of the organization and help to the cause of Customer loyalty, competitive edge in dynamic market place, merger and acquisition so on so forth ...
Information Life-cycle and evolution: Yes, Information has a lifecycle. Information derived from data should be following the information supply chain. Data becomes information when it represents business relationships. Data should be aligned to business model and process such that precise insight can be represented of customer behavior, how much acceptable risk can be taken and so on. Organization of information should be able to cater to wide range of strategies covering definition, policy, infrastructure and operation and functionality. For example - Data is born when customer places an order, which gets associated to identification definitions like customer, product, market .. Then goes thru order fulfillment and then customer service repair so on so forth. The data in the meantime goes through various transformations as it is related to financial, marketing, demand planning or predictive uses, in order to answer questions crucial to operating and optimizing business decisions. Finally, information has an end game. The customer moves away or the product is discontinued. The data is no longer updated, remains unused by the business and eventually become irrelevant both to the enterprise and the society in which the enterprise does business. As the volumes of data accumulate, the data warehouse becomes “obese.” Meanwhile, the data warehouse become entwined with mission-critical systems, impacting the performance of both transactional and decision support systems. This drive information mining with stale information and more resources to deep dive into a slice of information set for confirming the outliers found in the initial data set.
Managing Your Data Growth: A system that has been in production for several years is likely to contain a significant volume of data that is not used at all or used infrequently. Data warehouses often start big and get even bigger. The lifecycle of the data warehouse and the requirement to perform archiving shifts into the foreground. Enterprises engage in data archiving as part of an approach to information lifecycle management, of which data warehousing is an essential part. Archiving is the best way both to improve performance of the data warehouse (or transactional system) and to satisfy the requirements for data retention and security. This will enable improved ROI, information richness and better response when reaching for active and/or inactive data.
Visual representation of Information for Discovery: The human brain is good at doing some things and limited in others. For example, our brains is good at recognizing visual patterns, while they are able to remember relatively little from large amount of information. Primarily data analysis is making sense using comparison as individual facts mean nothing by themselves. Facts become meaningful when we compare them to one another. By displaying data in series of small graphs arranged as a visual cross-tab, which allows multiple dimensions to be compared simultaneously. This will allow users to see and compare patterns and trends of outlier or inconsistent behavior. Thus provide potential fraud candidate for further investigation.
Conforming Architecture: Fraud identification has a different approach than general Data warehouse or BI solution. In case of general BI solution, the measurement criteria is often a set of transaction quantifying success of a campaign or Sales Measures so on, however fraud would taking a subset of data and analyze association with scenarios by means of data and deep dive. As BI can provide model based information of trends, human interaction will identify the outlier cases for further investigation. Mature Business Intelligence architecture need to consider the commonalities and differentiators in their architecture to cater to these different audience needs. In addition, the deployment design of information architecture if not flexible enough then there will be high cost of reaching to the tip of the iceberg beyond that potential could be more investment for each scenario i.e unsustainable spiral.
Holistic approach: Fraud Management Lifecycle is dynamic, evolving, and BI solution architectures should be flexible enough to adaptive it. Effective fraud management requires a balance in the competing and complementary actions within the Information Lifecycle. Solutions can be defined based on past data trend, but the power of success lies with solutions that can embrace the new data to provide the insight.
Consolidation has left a lot of companies with multiple incompatible systems, inconsistent applied policies, more holds and less penetration in dynamic market place. Even with mature BI organization, fraud analytic can only be effective with ability to efficiently link with different data set and robust architecture.
Reference: Journal of Economic Crime Management
Statistics: The Fraud Management Lifecycle Theory
Information Life-cycle and evolution: Yes, Information has a lifecycle. Information derived from data should be following the information supply chain. Data becomes information when it represents business relationships. Data should be aligned to business model and process such that precise insight can be represented of customer behavior, how much acceptable risk can be taken and so on. Organization of information should be able to cater to wide range of strategies covering definition, policy, infrastructure and operation and functionality. For example - Data is born when customer places an order, which gets associated to identification definitions like customer, product, market .. Then goes thru order fulfillment and then customer service repair so on so forth. The data in the meantime goes through various transformations as it is related to financial, marketing, demand planning or predictive uses, in order to answer questions crucial to operating and optimizing business decisions. Finally, information has an end game. The customer moves away or the product is discontinued. The data is no longer updated, remains unused by the business and eventually become irrelevant both to the enterprise and the society in which the enterprise does business. As the volumes of data accumulate, the data warehouse becomes “obese.” Meanwhile, the data warehouse become entwined with mission-critical systems, impacting the performance of both transactional and decision support systems. This drive information mining with stale information and more resources to deep dive into a slice of information set for confirming the outliers found in the initial data set.
Managing Your Data Growth: A system that has been in production for several years is likely to contain a significant volume of data that is not used at all or used infrequently. Data warehouses often start big and get even bigger. The lifecycle of the data warehouse and the requirement to perform archiving shifts into the foreground. Enterprises engage in data archiving as part of an approach to information lifecycle management, of which data warehousing is an essential part. Archiving is the best way both to improve performance of the data warehouse (or transactional system) and to satisfy the requirements for data retention and security. This will enable improved ROI, information richness and better response when reaching for active and/or inactive data.
Visual representation of Information for Discovery: The human brain is good at doing some things and limited in others. For example, our brains is good at recognizing visual patterns, while they are able to remember relatively little from large amount of information. Primarily data analysis is making sense using comparison as individual facts mean nothing by themselves. Facts become meaningful when we compare them to one another. By displaying data in series of small graphs arranged as a visual cross-tab, which allows multiple dimensions to be compared simultaneously. This will allow users to see and compare patterns and trends of outlier or inconsistent behavior. Thus provide potential fraud candidate for further investigation.
Conforming Architecture: Fraud identification has a different approach than general Data warehouse or BI solution. In case of general BI solution, the measurement criteria is often a set of transaction quantifying success of a campaign or Sales Measures so on, however fraud would taking a subset of data and analyze association with scenarios by means of data and deep dive. As BI can provide model based information of trends, human interaction will identify the outlier cases for further investigation. Mature Business Intelligence architecture need to consider the commonalities and differentiators in their architecture to cater to these different audience needs. In addition, the deployment design of information architecture if not flexible enough then there will be high cost of reaching to the tip of the iceberg beyond that potential could be more investment for each scenario i.e unsustainable spiral.
Holistic approach: Fraud Management Lifecycle is dynamic, evolving, and BI solution architectures should be flexible enough to adaptive it. Effective fraud management requires a balance in the competing and complementary actions within the Information Lifecycle. Solutions can be defined based on past data trend, but the power of success lies with solutions that can embrace the new data to provide the insight.
Consolidation has left a lot of companies with multiple incompatible systems, inconsistent applied policies, more holds and less penetration in dynamic market place. Even with mature BI organization, fraud analytic can only be effective with ability to efficiently link with different data set and robust architecture.
Reference: Journal of Economic Crime Management
Statistics: The Fraud Management Lifecycle Theory
Monday, August 10, 2009
Analytic Solution - Prone to degrading performance?
As the desire for the enterprise to act quickly and navigate through the changing markets, this has mushroomed new generation of analytic solution to deal with the data growth and desire for discovering new insight. In past many years, I have noticed that when defining the solution for decision support, the first step has often been to build a quick solution without worrying about building sustainable infrastructure. But, soon these solutions starts hitting the wall, as they were either highly customized and or built with the least costly option!
As analytic applications are driving for prime time, organizations are faced with hard facts and consequences of their past decisions. With this increase of focus, core of Analytic solution for enhanced ROI needs to be built on the Enterprise information integration with tomorrow's needs in mind.
Capability to scale as system grows in size:
Pay attention to database, platform and network for handling of I/O for an acceptable through-put. Each system should be individually understood to understand the scalability choices to act appropriately to address the effect of growth. Especially for Analytic solutions, data integration and analytic processing are another choking point due to need for extraction of information from large data set effectively and efficiently. Effective management ingredients are key to the scalable solution.
Throwing more horse-power such that increasing processing power, more indexes so on, such brute force are short term solution before next crisis emerges. Managing scalability begins with defining an architecture that can start small but grow overtime in coordination with each component in the architecture physical or logical.
Often the case is that the actual usage facts/statistics are obtained after first couple of months of the solution use, hence most of the assumptions for usage should be critically weighed and considered. This should include the headroom for growth of physical architecture with consideration for multi-thread processing in all stages from migration to everyday operation.
Logical Architecture should ensure deployment mode with a clear understanding for what is required for tactical vs strategic decision making - when, what, where and who.
Poor Quality Data and Obsolete Content:
Managing the growth based on usage, subject focus, analytical and reporting capability can overcome costly engineering efforts under the umbrella of growth consequence. Emphasizing on the effort to capture the appropriate information (meta-data) when the data is created. Associated meta-data from the beginning would be crucial for the need of the information for decision making. Master Data management should be embedded and evolving process. Competitive advantage will be gained in the continued evaluation and improvement of the matching accuracy and trust worthy data and critical resource juice while processing at various stages.
Transforming the data:
Understand the infrastructure required to perform the ETL and ad-hoc front query is key to needs for tactical and strategic analytic needs. The stress on the transactional systems and analytic solutions are very different, eg. unlike transactional system, analytic solutions a based on utilization rates and scope of data, so on. In addition query parameters would vary quiet sharply leading to large data set. Addressing this would be a balancing act based on the need like freshness of the data, business events, security and privacy, aggregated view vs detail/trend view. Investment should not be purely dominated by tools, but in coordination of user's needs, experienced and balanced deployment team.
Operation Management:
Monitoring and preventing the bottleneck situation or system crash should be prime role of operation's team for today's global systems with ever tightening processing window. In addition, coordination with network management to deal with insufficient bandwidth, but provide acceptable system performance is critical to success of the solution. Console view of the operations with ability to highlight the alerts with defined threshold will enable the systems not to be in crisis mode.
Staging Data:
Key consideration should be given to separation of user experience from physical infrastructure. Semantic layer hides the complexity of underlying data sources, by providing a business representation of organizational data. The semantic layer also makes reusable report elements and powerful calculation capabilities available, allowing users to quickly access key information. In addition, you can use the semantic layer's metadata throughout your organization's BI solutions. Semantic layer should be supported by Enriched data layer for summary, details and slowly changing dimension. Deploying the KPIs at semantic layer vs at database level often causes the data fetch performance. Planning each layer with usage understanding, auditing and monitoring will enable system efficiency.
Change Management:
The pipeline of the changes should be sequenced such that it differentiates the core changes required for deploying an front end change. Deploying the foundational back-end elements and build on top of it to deliver the front end functionality will support the effort for the optimal return and scalability.
Scalability should be planned for, as early as pilot project phase to cope with consequences of growth.
As analytic applications are driving for prime time, organizations are faced with hard facts and consequences of their past decisions. With this increase of focus, core of Analytic solution for enhanced ROI needs to be built on the Enterprise information integration with tomorrow's needs in mind.
Capability to scale as system grows in size:
Pay attention to database, platform and network for handling of I/O for an acceptable through-put. Each system should be individually understood to understand the scalability choices to act appropriately to address the effect of growth. Especially for Analytic solutions, data integration and analytic processing are another choking point due to need for extraction of information from large data set effectively and efficiently. Effective management ingredients are key to the scalable solution.
Throwing more horse-power such that increasing processing power, more indexes so on, such brute force are short term solution before next crisis emerges. Managing scalability begins with defining an architecture that can start small but grow overtime in coordination with each component in the architecture physical or logical.
Often the case is that the actual usage facts/statistics are obtained after first couple of months of the solution use, hence most of the assumptions for usage should be critically weighed and considered. This should include the headroom for growth of physical architecture with consideration for multi-thread processing in all stages from migration to everyday operation.
Logical Architecture should ensure deployment mode with a clear understanding for what is required for tactical vs strategic decision making - when, what, where and who.
Poor Quality Data and Obsolete Content:
Managing the growth based on usage, subject focus, analytical and reporting capability can overcome costly engineering efforts under the umbrella of growth consequence. Emphasizing on the effort to capture the appropriate information (meta-data) when the data is created. Associated meta-data from the beginning would be crucial for the need of the information for decision making. Master Data management should be embedded and evolving process. Competitive advantage will be gained in the continued evaluation and improvement of the matching accuracy and trust worthy data and critical resource juice while processing at various stages.
Transforming the data:
Understand the infrastructure required to perform the ETL and ad-hoc front query is key to needs for tactical and strategic analytic needs. The stress on the transactional systems and analytic solutions are very different, eg. unlike transactional system, analytic solutions a based on utilization rates and scope of data, so on. In addition query parameters would vary quiet sharply leading to large data set. Addressing this would be a balancing act based on the need like freshness of the data, business events, security and privacy, aggregated view vs detail/trend view. Investment should not be purely dominated by tools, but in coordination of user's needs, experienced and balanced deployment team.
Operation Management:
Monitoring and preventing the bottleneck situation or system crash should be prime role of operation's team for today's global systems with ever tightening processing window. In addition, coordination with network management to deal with insufficient bandwidth, but provide acceptable system performance is critical to success of the solution. Console view of the operations with ability to highlight the alerts with defined threshold will enable the systems not to be in crisis mode.
Staging Data:
Key consideration should be given to separation of user experience from physical infrastructure. Semantic layer hides the complexity of underlying data sources, by providing a business representation of organizational data. The semantic layer also makes reusable report elements and powerful calculation capabilities available, allowing users to quickly access key information. In addition, you can use the semantic layer's metadata throughout your organization's BI solutions. Semantic layer should be supported by Enriched data layer for summary, details and slowly changing dimension. Deploying the KPIs at semantic layer vs at database level often causes the data fetch performance. Planning each layer with usage understanding, auditing and monitoring will enable system efficiency.
Change Management:
The pipeline of the changes should be sequenced such that it differentiates the core changes required for deploying an front end change. Deploying the foundational back-end elements and build on top of it to deliver the front end functionality will support the effort for the optimal return and scalability.
Scalability should be planned for, as early as pilot project phase to cope with consequences of growth.
Thursday, April 9, 2009
Finding Fraud with analytics
Fraud analytics starts with a theory. Theory has assumptions and some gut factor. Think about it, all our life from childhood to adult life we are involved in search-n-seek. Childhood days it's cookies, candies and so on, but as we grow up car keys, glasses, remote so on so forth; however the point to note is that the strategy to find things constantly evolves. Perhaps, to find fraud in business process and systems, the search-n-find skill need to be taken to the next level.
The detection strategy should be such that is proactive and constantly audited. But, based on experience one need to outline some assumptions to identify trees in the forest. The approach to find the tree in the forest should be such that it can be modeled and be repetitive processes. These models and processes can be deployed by IT teams for business to monitor and evolve the pattern. Sounds simple, but a properly designed fraud plan begins with simply looking for instances where a fraud scenario is most likely to occur, much like a search-and-find game.
Effective fraud plan also requires awareness, or the ability to interpret the data for the indicators, of the fraud scenario. While the simple fraud scenarios can be detected via a properly designed fraud data procedure, a fraud scenario with a sophisticated concealment strategy requires the ability to see through the concealment strategy.
1. List your assumptions based on high probable cases. The key considerations are to
understand the variations of the scenario that are caused by the fraud opportunity. This helps define the scope of the Fraud Audit.
2. Develop a fraud data profile with data, using the process of drawing a picture of a fraud scenario. For example, one variation of a false billing scheme through a false company is when the accounts payable takes over the identity of a dormant vendor on the database and charges invoices to a large cost center.
3. Structured step-by-step approach to identifying transactions consistent with a fraud scenario/assumption, as described through the fraud data profile.
4. Obtain pertinent data and their relation to the assumption.
5. Define data interrogation procedure - pattern & Frequency, identify outlier cases for good and bad both, Trends, GAP in business process, potential mistakes in data capture and transactional history, Master data accuracy
6. Define the KPI (Key performance Indicator) and monitor the indicators regularly
7. Prepare plan to respond to the indicator pattern. Evolve the KPIs for further sophistication and insight.
8. Once the culprits is identified monitor their behavior for firming up the plan. This will also help evolve the good vs bad outliers.
Search routines help focus identifying of “red flags” of the fraud scenario/assumption. By using data interpretation, one can develop reports or documentation and interpret the data.
Facts:
Insurance: In United States, about $67 billion is lost every year to fraudulent claim.(Federal Bureau of Investigation [FBI], 2003).
Telecommunications: $1.5 trillion phone industry loses approximately 10% to fraud, that is $150 billion at current estimates (Mena, 2003).
Bank Fraud: For the period of April 1, 1996 through September 30, 2002, the FBI received 207,051 Suspicious Activity Reports equaled approximately $7 billion in losses (U.S. Department of Justice [DOJ], 2002).
Money Laundering: United States Treasury officials estimate that as much as $300 billion is laundered annually, worldwide, with from $40 billion to $80 billion of this originating from drug profits made in the United States. (Mena, 2003).
Internet: According to Meridien Research, worldwide credit card fraud[the Internet component] will represent $15.5 billion in losses [annually] by 2005. However, if merchants adopt data mining technology now to help screen credit-card orders prior to processing, the widespread use of this technology is predicted to cut overall losses by two thirds to $5.7 billion in 2005” (Mena, 2003).
Credit Card: The numbers from the Nilson report indicate that issuer credit card fraud losses run approximately 1 billion dollars annually. This list does not even include debit card fraud, brokerage fraud, fraud at casinos, health care fraud, and other miscellaneous fraud types such as bankruptcy fraud
Journal of Economic Crime Management Spring 2004, Volume 2, Issue 2
Senator Everett Dirksen so aptly said, “A billion here a trillion there; the first thing you know, you’re talking about real money.”
Source: Journal of Economic Crime Management Spring 2004, Volume 2, Issue 2
Related Articles:
1. Fraud By the Book
2. Medicare Fraud
The detection strategy should be such that is proactive and constantly audited. But, based on experience one need to outline some assumptions to identify trees in the forest. The approach to find the tree in the forest should be such that it can be modeled and be repetitive processes. These models and processes can be deployed by IT teams for business to monitor and evolve the pattern. Sounds simple, but a properly designed fraud plan begins with simply looking for instances where a fraud scenario is most likely to occur, much like a search-and-find game.
Effective fraud plan also requires awareness, or the ability to interpret the data for the indicators, of the fraud scenario. While the simple fraud scenarios can be detected via a properly designed fraud data procedure, a fraud scenario with a sophisticated concealment strategy requires the ability to see through the concealment strategy.
1. List your assumptions based on high probable cases. The key considerations are to
understand the variations of the scenario that are caused by the fraud opportunity. This helps define the scope of the Fraud Audit.
2. Develop a fraud data profile with data, using the process of drawing a picture of a fraud scenario. For example, one variation of a false billing scheme through a false company is when the accounts payable takes over the identity of a dormant vendor on the database and charges invoices to a large cost center.
3. Structured step-by-step approach to identifying transactions consistent with a fraud scenario/assumption, as described through the fraud data profile.
4. Obtain pertinent data and their relation to the assumption.
5. Define data interrogation procedure - pattern & Frequency, identify outlier cases for good and bad both, Trends, GAP in business process, potential mistakes in data capture and transactional history, Master data accuracy
6. Define the KPI (Key performance Indicator) and monitor the indicators regularly
7. Prepare plan to respond to the indicator pattern. Evolve the KPIs for further sophistication and insight.
8. Once the culprits is identified monitor their behavior for firming up the plan. This will also help evolve the good vs bad outliers.
Search routines help focus identifying of “red flags” of the fraud scenario/assumption. By using data interpretation, one can develop reports or documentation and interpret the data.
Facts:
Insurance: In United States, about $67 billion is lost every year to fraudulent claim.(Federal Bureau of Investigation [FBI], 2003).
Telecommunications: $1.5 trillion phone industry loses approximately 10% to fraud, that is $150 billion at current estimates (Mena, 2003).
Bank Fraud: For the period of April 1, 1996 through September 30, 2002, the FBI received 207,051 Suspicious Activity Reports equaled approximately $7 billion in losses (U.S. Department of Justice [DOJ], 2002).
Money Laundering: United States Treasury officials estimate that as much as $300 billion is laundered annually, worldwide, with from $40 billion to $80 billion of this originating from drug profits made in the United States. (Mena, 2003).
Internet: According to Meridien Research, worldwide credit card fraud[the Internet component] will represent $15.5 billion in losses [annually] by 2005. However, if merchants adopt data mining technology now to help screen credit-card orders prior to processing, the widespread use of this technology is predicted to cut overall losses by two thirds to $5.7 billion in 2005” (Mena, 2003).
Credit Card: The numbers from the Nilson report indicate that issuer credit card fraud losses run approximately 1 billion dollars annually. This list does not even include debit card fraud, brokerage fraud, fraud at casinos, health care fraud, and other miscellaneous fraud types such as bankruptcy fraud
Journal of Economic Crime Management Spring 2004, Volume 2, Issue 2
Senator Everett Dirksen so aptly said, “A billion here a trillion there; the first thing you know, you’re talking about real money.”
Source: Journal of Economic Crime Management Spring 2004, Volume 2, Issue 2
Related Articles:
1. Fraud By the Book
2. Medicare Fraud
Wednesday, April 8, 2009
BI is not only tool deployment, there is more to it
According to Gartner Inc,

The economy may be in recession, but the business intelligence (BI) platform market is still on pace for growth over the next three years

With shrinking IT budget and projection for rest of 2009 looking bleak, organizations need to look into dysfunctional processes that have torpedoed many Business Intelligence (BI) efforts in the past. As BI is driven by data, BI based business decisions should consume data of high integrity. Bottom line - BI (Business Intelligence) for tomorrow need to be moving away from disparate tools and island of data, into an "information-centric" enterprise.
Vendor packages - Oracle Corp, Microsoft, IBM, SAP,.. come with a big promise BI solution. But this often results in ending up with multiple BI solutions in organization's infrastructure that don't work well together, and the quest for "The BI solution" that gives you a consolidated view of all your processes and transactions remains a mirage.
Remember, there may not be perfect data management to start on BI project. I have experienced in the past, Data management is complicated because data in most large enterprises are not organized appropriately or atomic enough to generate appropriate reports consistently. But data without effective data management is rarely information in the larger sense. Poor data quality leads to poor decision
1. Quality of Data: Organizations must establish processes or set of automated controls to identify data quality issues in incoming data and block low-quality data from entering the data warehouse. Implement the process with automated audit trails and alerting using tools, custom code, data quality technology, data integration tools or a combination of these to achieve optimal ETL (Extraction Transformation and Loading) function.
2. Semantics of Data
Semantics data layer should contain the appropriate granularity and derived data based on the usage needs. However, ensure the data in data warehouse is at the most atomic / granular as possible for derivation, but all of this data should not be then made available in semantic layer for BI tools to function. At the same time maintain data definition and derived data consistency. Derived data should have a definition and owner assigned. Ensure to review the data ETL with wrt Business Process with the users, so that they are participants in the journey and not just IT driven activity. Another important participant in the semantics layer is master data. This non transactional data refered as Master data e.g. Customers, Products, Sales Region, Sales Channels, Suppliers, Manufacturers, e.t.c. should be defined with appropriate attributes and consistency for the best value for BI deployment.
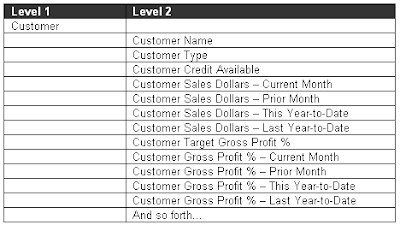
3. Usage Driven Data Model: The goal is to resolve all the semantic differences before designing the data structures for the data warehouse. Whipping data into shape means having expert data modelers spend most of their time working with the business users who understand how the data is intended to be used. Data Models in Semantic layer should be optimized for usage, but remember one shoe can not fit all. If required effort should be made to provide subject area based or user community based semantic models to ensure consistent consumption of data for intended Audience to reach the desired information. Also note, data modeling with home work done on usage pattern using Technology & methodologies plays an important role in deriving how to segment the data for different type of users like Executives, Management, operational team and analysts for their optimal use.
4. Traceability to lowest level
Remember, data quality cannot be solved by the IT department with a tool. Business users must be engaged to determine what is "good enough" in terms of data quality. And don't mistake data accuracy for relevance. That leads to the next big surprises. For all listed data elements, trace them back to their source system(s) and document what transformations they went through before they were printed on the report, displayed on the screen, or written to the extract file. This is where the hidden semantic differences are revealed. Two reports, maybe for two different departments displaying Net Sales, are found to use slightly different calculations-and of course the numbers don't match-how could they? It's found that data on two different reports, while generally identical, is sometimes different. The tracing exercise may reveal that one report is sourced from an unadjusted file and the other report is sourced from the same file, but only after twice-yearly adjustments are made.

Review the completed element list with definitions and traced mappings with the business users and validate that the document is a complete and correct semantic representation. Facilitate joint sessions with the business users and IT to develop and come to consensus on new terms as needed-e.g. "commission" sales. On the other hand, it may be more appropriate to redefine one or more transformation formulas to conform dissimilar elements. Lastly, base hierarchies does not often resolve the data navigation issues, hence derived dimension should be a key consideration.
5. Strong drivers: BI deployment without strong driver by leadership team will not achieve acceptable results. The biggest problem with BI has always been getting the business teams to agree on what can be made into common definition. From an infrastructure perspective, it is important to try to normalize that relationship between IT and Business, but it's also important to have capable leaders are participating to guide the the IT team vs leaders driving what is right for the management. Similarly, Business manager driven by numbers, but keeping them close to the heart also causes challenges to reconcile the definitions and management. They don't want to have transparency by a dashboard or scorecard or report. Transparency correlates with better business performance. Strong business sponsors who believe in a fact-based approach to management and IT people who can map agreed-upon metrics to the data.
6. Vendor Selection: There is plenty of pressure to go with the standard vendor. The CFO who authorized millions of dollars for ERP may balk at spending more for BI and corporate performance management tools. But "one-stop shopping" doesn't necessarily lower the total cost of ownership or deliver the best fit for your enterprise's needs. Determination of which BI functions are delivered by your enterprise application vendor and compare these functions with those offered by other BI system vendors. Perform evaluation to arrive at the results, often phase zero is better suited before large expense on BI deployment. What ever tool is selected for deployment, do not develop custom functions to the extent that they become high cost of ownership.
In order to be effective with all the mentioned points, you again have to have data management to go along with it and maintain transparency, and BI is a good way to inform that effect, to tell you where redundancies are and study the state of your data.
The economy may be in recession, but the business intelligence (BI) platform market is still on pace for growth over the next three years
With shrinking IT budget and projection for rest of 2009 looking bleak, organizations need to look into dysfunctional processes that have torpedoed many Business Intelligence (BI) efforts in the past. As BI is driven by data, BI based business decisions should consume data of high integrity. Bottom line - BI (Business Intelligence) for tomorrow need to be moving away from disparate tools and island of data, into an "information-centric" enterprise.
Vendor packages - Oracle Corp, Microsoft, IBM, SAP,.. come with a big promise BI solution. But this often results in ending up with multiple BI solutions in organization's infrastructure that don't work well together, and the quest for "The BI solution" that gives you a consolidated view of all your processes and transactions remains a mirage.
Remember, there may not be perfect data management to start on BI project. I have experienced in the past, Data management is complicated because data in most large enterprises are not organized appropriately or atomic enough to generate appropriate reports consistently. But data without effective data management is rarely information in the larger sense. Poor data quality leads to poor decision
1. Quality of Data: Organizations must establish processes or set of automated controls to identify data quality issues in incoming data and block low-quality data from entering the data warehouse. Implement the process with automated audit trails and alerting using tools, custom code, data quality technology, data integration tools or a combination of these to achieve optimal ETL (Extraction Transformation and Loading) function.
2. Semantics of Data
Semantics data layer should contain the appropriate granularity and derived data based on the usage needs. However, ensure the data in data warehouse is at the most atomic / granular as possible for derivation, but all of this data should not be then made available in semantic layer for BI tools to function. At the same time maintain data definition and derived data consistency. Derived data should have a definition and owner assigned. Ensure to review the data ETL with wrt Business Process with the users, so that they are participants in the journey and not just IT driven activity. Another important participant in the semantics layer is master data. This non transactional data refered as Master data e.g. Customers, Products, Sales Region, Sales Channels, Suppliers, Manufacturers, e.t.c. should be defined with appropriate attributes and consistency for the best value for BI deployment.

3. Usage Driven Data Model: The goal is to resolve all the semantic differences before designing the data structures for the data warehouse. Whipping data into shape means having expert data modelers spend most of their time working with the business users who understand how the data is intended to be used. Data Models in Semantic layer should be optimized for usage, but remember one shoe can not fit all. If required effort should be made to provide subject area based or user community based semantic models to ensure consistent consumption of data for intended Audience to reach the desired information. Also note, data modeling with home work done on usage pattern using Technology & methodologies plays an important role in deriving how to segment the data for different type of users like Executives, Management, operational team and analysts for their optimal use.
4. Traceability to lowest level
Remember, data quality cannot be solved by the IT department with a tool. Business users must be engaged to determine what is "good enough" in terms of data quality. And don't mistake data accuracy for relevance. That leads to the next big surprises. For all listed data elements, trace them back to their source system(s) and document what transformations they went through before they were printed on the report, displayed on the screen, or written to the extract file. This is where the hidden semantic differences are revealed. Two reports, maybe for two different departments displaying Net Sales, are found to use slightly different calculations-and of course the numbers don't match-how could they? It's found that data on two different reports, while generally identical, is sometimes different. The tracing exercise may reveal that one report is sourced from an unadjusted file and the other report is sourced from the same file, but only after twice-yearly adjustments are made.

Review the completed element list with definitions and traced mappings with the business users and validate that the document is a complete and correct semantic representation. Facilitate joint sessions with the business users and IT to develop and come to consensus on new terms as needed-e.g. "commission" sales. On the other hand, it may be more appropriate to redefine one or more transformation formulas to conform dissimilar elements. Lastly, base hierarchies does not often resolve the data navigation issues, hence derived dimension should be a key consideration.
5. Strong drivers: BI deployment without strong driver by leadership team will not achieve acceptable results. The biggest problem with BI has always been getting the business teams to agree on what can be made into common definition. From an infrastructure perspective, it is important to try to normalize that relationship between IT and Business, but it's also important to have capable leaders are participating to guide the the IT team vs leaders driving what is right for the management. Similarly, Business manager driven by numbers, but keeping them close to the heart also causes challenges to reconcile the definitions and management. They don't want to have transparency by a dashboard or scorecard or report. Transparency correlates with better business performance. Strong business sponsors who believe in a fact-based approach to management and IT people who can map agreed-upon metrics to the data.
6. Vendor Selection: There is plenty of pressure to go with the standard vendor. The CFO who authorized millions of dollars for ERP may balk at spending more for BI and corporate performance management tools. But "one-stop shopping" doesn't necessarily lower the total cost of ownership or deliver the best fit for your enterprise's needs. Determination of which BI functions are delivered by your enterprise application vendor and compare these functions with those offered by other BI system vendors. Perform evaluation to arrive at the results, often phase zero is better suited before large expense on BI deployment. What ever tool is selected for deployment, do not develop custom functions to the extent that they become high cost of ownership.
In order to be effective with all the mentioned points, you again have to have data management to go along with it and maintain transparency, and BI is a good way to inform that effect, to tell you where redundancies are and study the state of your data.
Subscribe to:
Posts (Atom)



